Algorithms: Introduction
Overview
Machine learning algorithms are sets of instructions that enable computers to learn from data, identify patterns, and make predictions without explicit programming.
What you can do with machine learning algorithms
Machine learning algorithms help you answer questions that are too complex to answer through manual analysis.
Use cases for machine learning algorithms typically fall into one of these categories:
- Predict a target,
- Find unusual data points,
- Predict values,
- See how values change over time,
- Discover similarities,
- Classification
These algorithms form the backbone of machine learning systems, allowing machines to improve their performance over time as they process more data.
At their core, machine learning algorithms:
- Analyze
large amounts of data - Discover
patternsandrelationships - Make
decisions or predictionsbased on the learned patterns
Machine learning algorithms are typically categorized into three main types:
SupervisedLearning: algorithms make predictions based on a set of labeled examples that you provide.- This technique is useful when you know what the outcome should look like.
UnsupervisedLearning: the data points aren’t labeled—the algorithm labels them for you by organizing the data or describing its structure.- This technique is useful when you don’t know what the outcome should look like.
ReinforcementLearning: uses algorithms that learn from outcomes and decide which action to take next.- After each action, the algorithm receives feedback that helps it determine whether the choice it made was correct, neutral, or incorrect.
- It’s a good technique to use for automated systems that have to make a lot of small decisions without human guidance.
- For example, you’re designing an autonomous car, and you want to ensure that it’s obeying the law and keeping people safe. As the car gains experience and a history of reinforcement, it learns how to stay in its lane, go the speed limit, and brake for pedestrians.
Machine learning algorithms are mathematical models that implement a finite set of unambiguous step-by-step instructions to achieve a specific goal, such as classification, regression, or clustering. They utilize statistical techniques to enable computers to “learn” from data without being explicitly programmed[1].
Most Relevant Algorithms
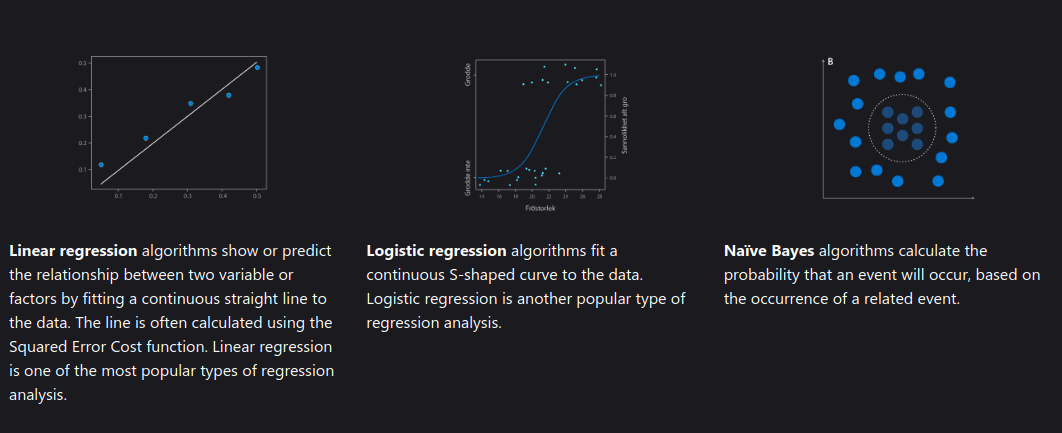
Linear Regression
Linear regression is used to predict continuous values by finding the best-fit line between input and output variables.
- Use case: Predicting house prices based on square footage.
Linear regression minimizes the difference between actual and predicted values using the method of least squares to fit a linear relationship between dependent and independent variables[4].
Logistic Regression
Logistic regression predicts probabilities and assigns data points to binary classes.
- Use case: Predicting whether an email is spam or not
Logistic regression uses a logistic function to model the probability of a binary outcome, transforming the output of a linear combination of features into a value between 0 and 1[4].
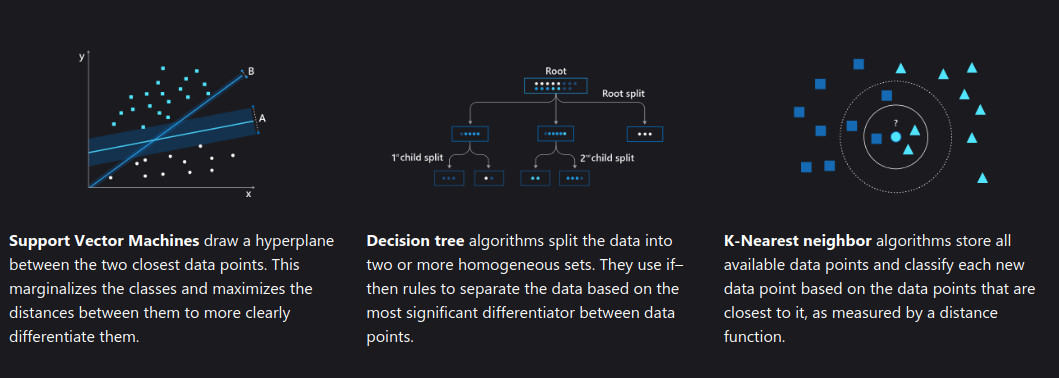
Decision Trees
Decision trees make predictions by following a tree-like model of decisions based on feature values.
- Use case: Classifying patients based on symptoms
Decision trees recursively split the data based on feature values, creating a tree structure where each internal node represents a decision based on a feature, each branch represents an outcome of that decision, and each leaf node represents a class label or numerical value[4].
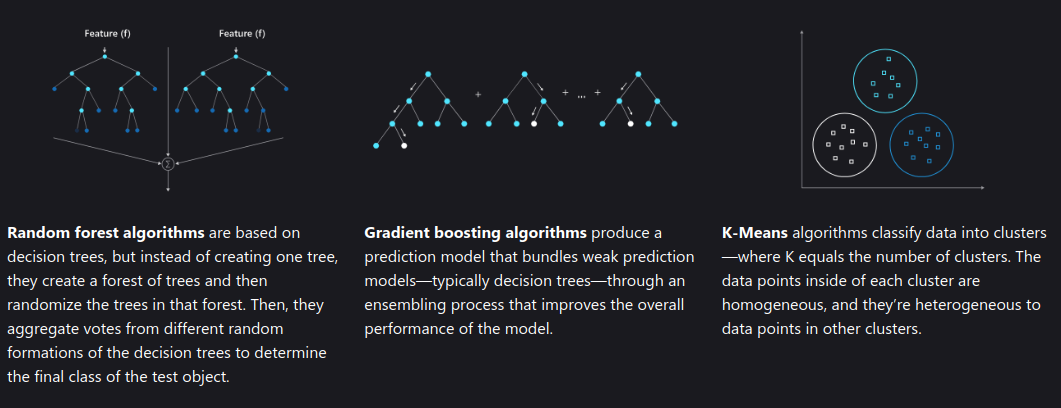
Random Forest
Random Forest is an ensemble learning method that constructs multiple decision trees and merges their predictions.
- Use case: Predicting customer churn
Random Forest builds multiple decision trees on randomly selected subsets of the training data and features, then aggregates their predictions through voting (for classification) or averaging (for regression) to improve accuracy and reduce overfitting[7].
Support Vector Machines (SVM)
SVM finds the optimal hyperplane that best separates different classes in high-dimensional space.
- Use case: Image classification
SVM constructs a hyperplane or set of hyperplanes in a high-dimensional space to maximize the margin between different classes, effectively creating a decision boundary for classification or regression tasks[4].
Examples in Python
These examples demonstrate the basic structure of implementing machine learning algorithms in Python. Each algorithm requires data preparation, model initialization, training, and prediction steps[2][8].
Here are simple examples of how to implement some of these algorithms using Python and the scikit-learn library:
Linear Regression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Assuming X and y are your feature and target variables
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LinearRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)Logistic Regression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# Assuming X and y are your feature and target variables
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LogisticRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)Random Forest
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Assuming X and y are your feature and target variables
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
predictions = model.predict(X_test)Citations:
- [1] Machine learning algorithms
- [2] Top 10 Python Machine Learning Algorithms
- [3] Machine Learning with Python Tutorial
- [4] Machine Learning Algorithms
- [5] What are Machine Learning Algorithms in Python?
- [6] Machine Learning Algorithms Gist
- [7] 10 Algorithms Machine Learning Engineers Need to Know
- [8] Machine Learning in Python Step-by-Step